
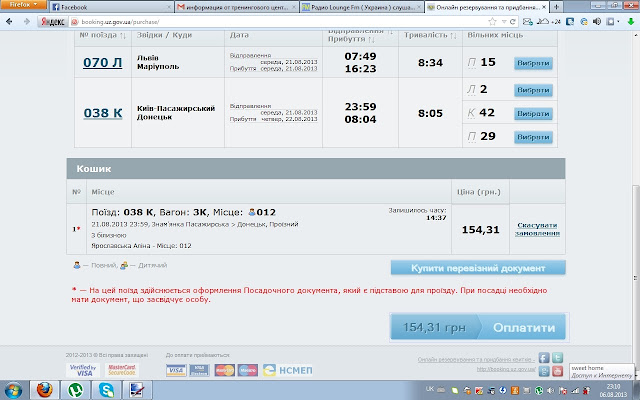
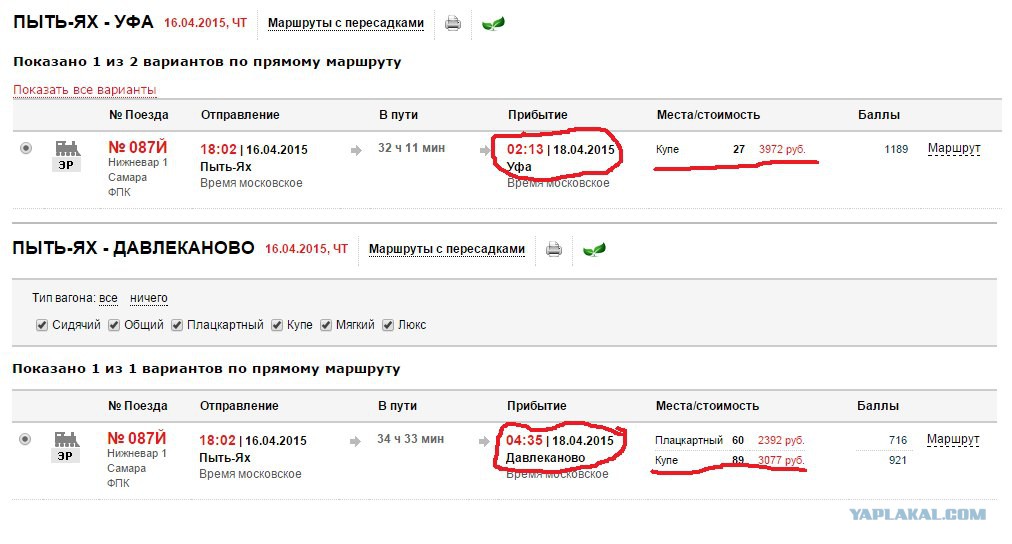
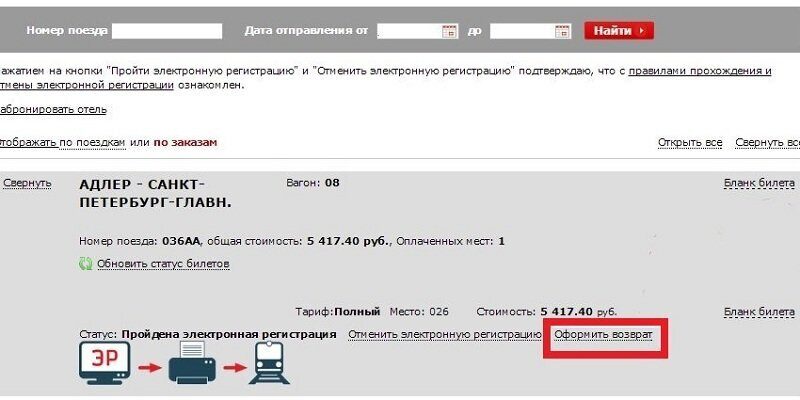
Содержание
Spartak Moscow Football Club — the official website
Russia Cup
Zenit
Spartak
Krestovsky Stadium
Reportage
Friendly matches
Spartak
23 : 12 : 28
dayshoursminutes
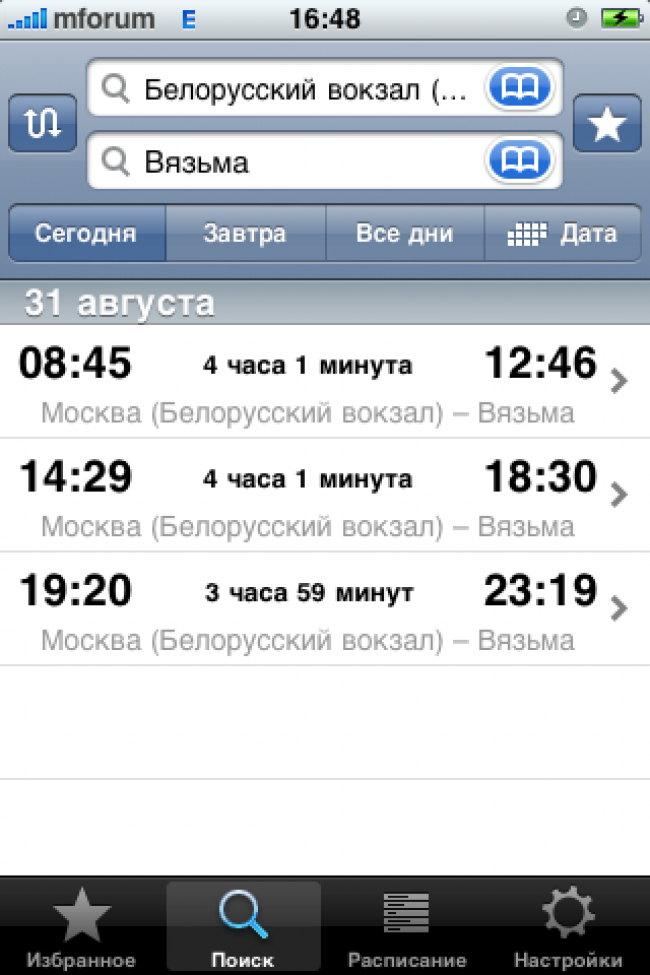
find flat
Jebel Ali
Levski
Jebel Ali
Friendly matches
Spartak
28 : 06 : 28
dayshoursminutes
Botev
Jebel Ali
Russia Cup
Zenit
Spartak
Krestovsky Stadium
Reportage
Friendly matches
Spartak
23 : 12 : 28
dayshoursminutes
find flat
Jebel Ali
Levski
Jebel Ali
Friendly matches
566Z»>27 January, 10:00
Spartak
28 : 06 : 28
dayshoursminutes
Botev
Jebel Ali
November
su
mo
tu
we
th
fr
sa
1
2
3
4
1 : 1
6
7
8
9
10
11
1 : 2
13
14
15
16
17
18
19
20
21
22
2 : 1
24
25
26
0 : 0
28
29
30
December
su
mo
tu
we
th
fr
sa
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
January
su
mo
tu
we
th
fr
sa
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
0 : 0
23
24
25
26
0 : 0
28
29
30
31
NewsAll news
Promes is the best player of the year! Sport-Express Award23 December 12:00Excursion tour as a gift for the New Year!18 December 12:33The dreams of young patients have come true!16 December 17:31Daniil Zorin extended the contract with Spartak16 December 16:30Flamengo bought Ayrton’s transfer from Spartak16 December 16:27We will play with Levski on January 2213 December 15:25
Do you want to be the first to know the news of Spartak?
subscribe
By entering my e-mail and clicking the «Subscribe» button, I agree to receive advertising and information mailings
tournament table
full table
1
Zenit
17
42
2
Spartak Moscow
17
36
3
Rostov
17
35
4
Dinamo Moskva
17
29
5
CSKA Moscow
17
29
Special offers
Rent of fields in “Sokolniki”
Book
VIP-Lodges Opening Bank Arena
Book
Rent of fields in “Sokolniki”
Book
VIP-Lodges Opening Bank Arena
Book
Rent of fields in “Sokolniki”
Book
VIP-Lodges Opening Bank Arena
Book
Video
All video
Spartak and MONOCHROME: limited collection
Promes and Melyoshin at the All-Star Game and Cup draw
Crazy last minutes and first place in the group!
Dzhikiya after Zenit
Chernov — about his fate and the desire to become an agent
 spartak.com/en/catalog/forma/shapka-ushanka-uteplennaya-s-iskustvennym-mekhom-krasnaya-krasnyy-sh011″>Шапка ушанка (утепленная с искуственным мехом) красная
spartak.com/en/catalog/forma/shapka-ushanka-uteplennaya-s-iskustvennym-mekhom-krasnaya-krasnyy-sh011″>Шапка ушанка (утепленная с искуственным мехом) красная1 990₽
Шапка ушанка (утепленная с искуственным мехом) красная
1 990₽
To cart
Худи MONOCHROME for SPARTAK
22 000₽
Худи MONOCHROME for SPARTAK
one size
22 000₽
To cart
Пуховик MONOCHROME for SPARTAK
59 000₽
Пуховик MONOCHROME for SPARTAK
one size
59 000₽
To cart
 spartak.com/en/catalog/forma/nabor-elochnykh-igrushek-igrovaya-forma-steklo-krasno-belyy-sm020405711″>Набор елочных игрушек Игровая форма (стекло)
spartak.com/en/catalog/forma/nabor-elochnykh-igrushek-igrovaya-forma-steklo-krasno-belyy-sm020405711″>Набор елочных игрушек Игровая форма (стекло)1 290₽
Набор елочных игрушек Игровая форма (стекло)
one size
1 290₽
To cart
Набор новогодних шаров (6 шт)
1 390₽
Набор новогодних шаров (6 шт)
one size
1 390₽
To cart
Футболка поло ретро «Спартак»
4 990₽
Футболка поло ретро «Спартак»
4 990₽
To cart
 spartak.com/en/catalog/forma/futbolka-retro-spartak-cherno-krasnyy-smttde1011024650″>Футболка ретро «Спартак»
spartak.com/en/catalog/forma/futbolka-retro-spartak-cherno-krasnyy-smttde1011024650″>Футболка ретро «Спартак»4 990₽
Футболка ретро «Спартак»
4 990₽
To cart
Футболка поло ретро «Спартак» с жаккардом
4 990₽
Футболка поло ретро «Спартак» с жаккардом
4 990₽
To cart
Свитер ретро «Спартак»
5 990₽
Свитер ретро «Спартак»
5 990₽
To cart
 spartak.com/en/catalog/forma/kastomizirovannaya-yandeks-stantsiya-layt-spartak-krasnyy-yndx-00025″>Кастомизированная Яндекс.Станция Лайт «Spartak»
spartak.com/en/catalog/forma/kastomizirovannaya-yandeks-stantsiya-layt-spartak-krasnyy-yndx-00025″>Кастомизированная Яндекс.Станция Лайт «Spartak»6 490₽
Кастомизированная Яндекс.Станция Лайт «Spartak»
onesize
6 490₽
To cart
Club trophies
12
USSR championship
10
Cup of USSR
10
Russian Premier League
4
Cup of Russia
1
Super Cup of Russia
Spartak Moscow Official App
The only official Spartak Moscow news app brings you the latest news, videos, match scores, notifications about the First, Youth and Academy Teams.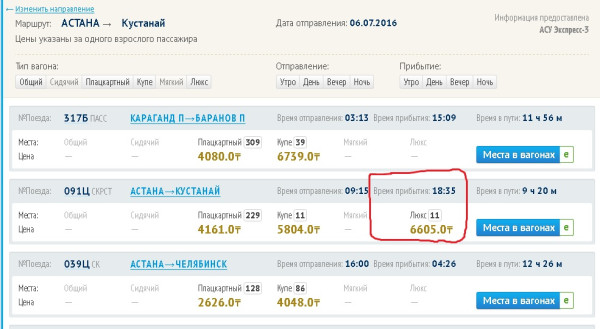 It also gives you full access to the official club shop and ticket purchases.
It also gives you full access to the official club shop and ticket purchases.
Our applications
Сравнение платформ обратного поиска изображений | Исследования в области безопасности — DomainTools
Блог General Infosec
10.09.2019
Поделиться этой записью
ДоменИнструменты
@DomainTools
Обзор
Это будет еще одна из, надеюсь, длинной серии практических сообщений в блоге OSINT от команды исследователей безопасности здесь, в DomainTools. На этот раз я кратко сравню возможности обратного поиска изображений в некоторых основных поисковых системах изображений. Мы рассмотрим Google, Yandex, Bing и TinEye. Надеюсь, вы уже знакомы с этими поисковыми системами, но если нет, этот пост — хороший ускоренный курс о том, какие результаты вы можете ожидать от каждой из них.
Сначала мы попросим Эмили дать обзор обратного поиска изображений, а затем я проведу несколько сравнений между самыми популярными поисковыми системами изображений.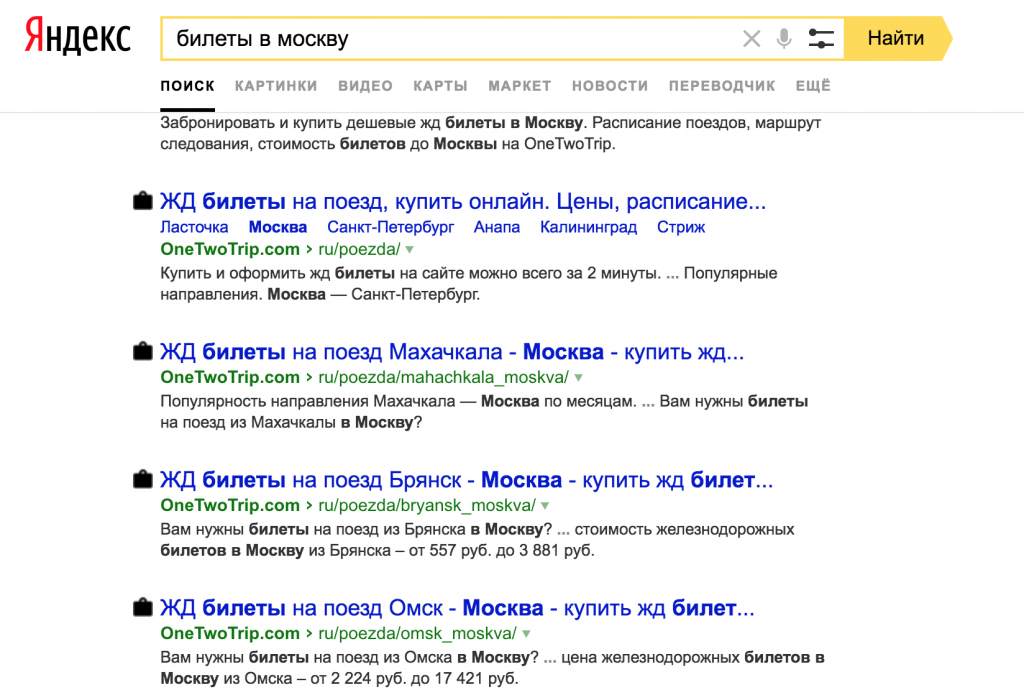 Мы не будем рассматривать какие-либо более сложные аспекты анализа изображений, а вместо этого сосредоточимся исключительно на том, что вы можете ожидать при загрузке изображений для реверсирования.
Мы не будем рассматривать какие-либо более сложные аспекты анализа изображений, а вместо этого сосредоточимся исключительно на том, что вы можете ожидать при загрузке изображений для реверсирования.
Обратный поиск изображений
В исследованиях безопасности мы много имеем дело с различными типами данных: IOC, исполняемые файлы вредоносных программ, отчеты и многое другое. Одним из типов данных, который часто может быть упущен из виду, являются изображения, такие как фотографии профиля в сообщениях на форуме, фотографии в рекламе вредоносных программ и многое другое. Выполняя поиск по этим изображениям различными способами, можно многое узнать о предмете вашего исследования.
Для некоторых расследований может быть достаточно обратного поиска изображений с помощью обычной поисковой системы, такой как Google или Bing. Например, если вы столкнулись с незнакомым логотипом, простой обратный поиск изображения может вернуть информацию о происхождении логотипа, которая может быть вам полезна, например информацию о бренде или местонахождении.
Например, в ходе расследования я наткнулся на аватар, используемый автором вредоносного ПО, которого я расследовал. Аватар казался специфическим, но я не был с ним знаком и задавался вопросом, не поможет ли мне узнать больше об авторе вредоносного ПО, узнав больше об аватаре.
В этом примере я зашел на images.google.com и щелкнул значок камеры в строке поиска.
Оттуда вы можете выбрать, следует ли загрузить изображение из ваших файлов или вставить URL-адрес изображения. Я загрузил аватар и нажал «Поиск по изображению». Google быстро возвращает страницу с изображением, которое я загрузил, возможным поиском по теме, а также несколькими статьями и страницами в Википедии, связанными с изображением.
В данном случае изображение, которое я загрузил, было достаточно уникальным, чтобы я мог узнать, что это изображение тесно связано с российскими преступными организациями, что помогло сузить круг вопросов, которые могут быть объектом моего расследования. по крайней мере, увлечься Россией).
по крайней мере, увлечься Россией).
Иногда Google может не выдавать достаточно конкретных результатов; в этих случаях также может быть полезно попробовать обратный поиск изображений с помощью Яндекса, Bing или TinEye.
Иногда при обратном поиске изображения может быть полезно каким-либо образом изменить исходное изображение, чтобы получить наилучшие результаты. Например, иногда изображение может быть опубликовано и заявлено как оригинальное, но на самом деле это просто перевернутая/перевернутая версия существующей фотографии. Перевернув фотографию, а затем выполнив ее поиск, вы сможете найти дополнительные результаты, которые могли не быть возвращены при поиске только одной фотографии. Тщательная обрезка также может дать гораздо лучшие результаты, поскольку другие объекты на фотографиях могут привести к тому, что поисковая система сфокусируется не на том объекте.
Хотя изображения и фотографии не являются самой распространенной информацией, с которой исследователи сталкиваются в своих исследованиях, эти тактики все же могут оказаться полезными в тех случаях, когда вы пытаетесь идентифицировать логотип или аватар, геолокацию фотографии или идентифицировать лицо на фотографии.
Я надеюсь, что это руководство было полезным!
– Эмили Хакер
 Я надеюсь, что это руководство было полезным!
Я надеюсь, что это руководство было полезным!Сравнение платформ для обратного поиска изображений
Лучший веб-сайт для обратного поиска изображений: Всего .
На дворе 2019 год, вот результаты, так что мы все можем вернуться в Twitter, Tik-Tok или что-то еще.
Сравнительная таблица возможностей обратного поиска изображений (по состоянию на август 2019 г.)
Я чувствую, что все эти двигатели имеют большое количество достоинств для каждой категории. Эти оценки основаны на моих личных предубеждениях и опыте во время расследования.
Претенденты
Картины Google
Google делает все возможное, чтобы определить, кто является объектом изображения, а не кто. Результаты обычно делятся на три раздела: несколько результатов поиска того, что, по мнению алгоритма, находится на фотографии, визуально похожие (но не идентичные) результаты и страницы с идентичными изображениями.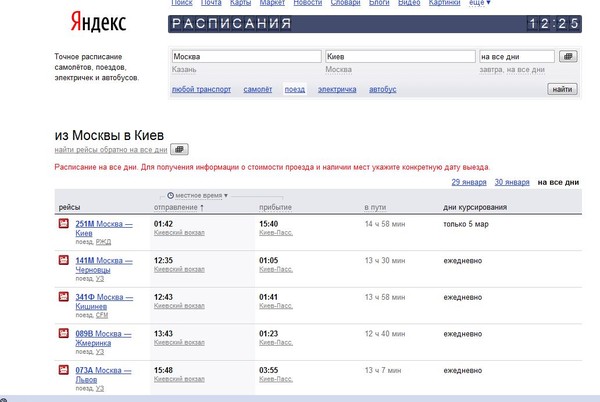 Между этими тремя разделами и возможностью выполнения дополнительных размеров одинаковых изображений Google является сильным реверсивным ресурсом. Недостатком является то, что многие сопоставления сосредоточены на социальных темах, поэтому, если тема вашего поиска изображений неизвестна, вы можете не получить качественных результатов. Поиск также ограничивается одной тематикой, поэтому, предполагая ввод фотографии дома у озера с горами, вы получите не фотографии домов у озера с горами, а просто визуально похожие дома, без учета озер или горы.
Между этими тремя разделами и возможностью выполнения дополнительных размеров одинаковых изображений Google является сильным реверсивным ресурсом. Недостатком является то, что многие сопоставления сосредоточены на социальных темах, поэтому, если тема вашего поиска изображений неизвестна, вы можете не получить качественных результатов. Поиск также ограничивается одной тематикой, поэтому, предполагая ввод фотографии дома у озера с горами, вы получите не фотографии домов у озера с горами, а просто визуально похожие дома, без учета озер или горы.
Яндекс Картинки
Яндекс, аналог российского Google, является золотой жилой для обратного поиска изображений. Он предоставляет дополнительные размеры одного и того же изображения, визуально похожие изображения и множество результатов, где похожие изображения представлены на страницах. Яндекс, как правило, является самой сильной поисковой системой для сопоставления лиц и определения местоположения.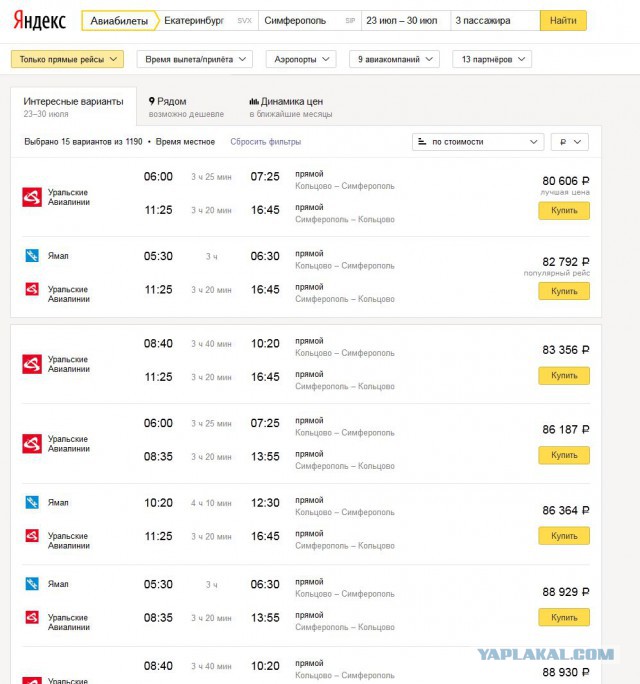 Если у вас есть фотография малоизвестного изгиба реки где-нибудь в Европе (спасибо Арику!), скорее всего, вы найдете там какие-то результаты.
Если у вас есть фотография малоизвестного изгиба реки где-нибудь в Европе (спасибо Арику!), скорее всего, вы найдете там какие-то результаты.
Изображения Bing
В Bing есть уникальная функция, которая мне очень нравится, — вы можете обрезать области фотографии и видеть результаты в реальном времени. Это отлично подходит для высококачественных изображений с большим количеством идентифицируемых объектов. Кроме того, по сравнению с Google, Bing пытается идентифицировать элементы на фотографии и находить изображения, содержащие все эти элементы. Таким образом, изображение старинного автомобиля, припаркованного рядом с деревом, вызовет совпадения, содержащие дерево и старинный автомобиль, тогда как Google выбирает один сильный предмет и следует за ним. Bing также отличается тем, что пытается заблаговременно идентифицировать лица, продукты и другие элементы на изображениях. Изображение высокой четкости нескольких известных предметов выделит каждый из них.
TinEye
Первоначальная единственная цель TinEye заключалась в поиске других размеров одного и того же изображения, и в течение многих лет он обеспечивал именно это. Я считаю, что за последний год или около того они активизировали свой алгоритм сопоставления и теперь сопоставляют больше визуально похожих изображений. Это означает, что вы, вероятно, найдете здесь свое изображение, используемое в других изображениях, и если это фотография, вы можете найти другие фотографии с точно такой же композицией. Здесь я хочу отметить, что TinEye не следует рассматривать как прямого конкурента этим другим движкам. TinEye полностью фокусируется на поиске другого использования того же изображения, что обычно делает его победителем при работе с чисто цифровыми медиа (аватары, логотипы, кнопки и т. д.). Я лично нашел его полезным для отслеживания аватаров пользователей между форумами, где у них может быть другое имя пользователя.
Избранные примеры
Для этого сравнения мы рассмотрим следующие изображения. Они не отражают всех нюансов этих поисковых систем, но дают хорошее представление об удивительных различиях между ними.
- Логотип DomainTools
- Скриншот The Plague (Fisher Stevens) от Hackers
- Логотип культа мертвой коровы
- Фотография Центрального железнодорожного вокзала Милана, сделанная одним из членов нашей команды
- Немного форумного чутья от HackForums
Я обобщил результаты ниже, но не забудьте нажать на эскизы , чтобы лучше понять точные результаты.
Логотип Domaintools
- Google . Выполняет задание на задание.
- Яндекс также нацелен на DomainTools, но в первую очередь идет на Twitter. Удивительно, но в результатах есть подозрительно похожие логотипы…
- Bing не идентифицирует DomainTools напрямую, но показывает изображения из блога DomainTools и нашей страницы LinkedIn.
- TinEye отдает предпочтение Твиттеру, вероятно, потому, что я вытащил это изображение из Твиттера.
 Удивительно, но в результатах есть подозрительно похожие логотипы…
Удивительно, но в результатах есть подозрительно похожие логотипы…
Чума (Фишер Стивенс) от хакеров
- Google идентифицирует это как «хакерские хакеры», а это то, что я бы хотел Google, если бы я хотел, чтобы это было так. Он четко идентифицирует хакеров в результатах.
- Яндекс показывает в основном одинаковые скрины с разных торрент-сайтов, а также ряд других картинок The Plague (не только Фишера Стивенса).
- Bing действительно впечатляет и идентифицирует Фишера Стивенса как актера на картинке. Он также помечает изображение как «Hacker Movie».
- TinEye показывает несколько результатов для торрент-сайтов.
 Он также помечает изображение как «Hacker Movie».
Он также помечает изображение как «Hacker Movie».Cult of the Dead Cow Logo
- Google Drugs This A. A. Визуально похожие изображения имеют огненную или красную/черепную тематику.
- Яндекс выбивает это из парка, он показывает страницы Культа мертвой коровы, а также несколько других изображений, которые используют то же самое изображение черепа.
- Bing показывает нам изображения огня и фениксов.
- TinEye интересно показывает нам другие изображения, основанные на той же стоковой фотографии, но без прямых дубликатов.
A Фотография центрального железнодорожного вокзала Милана
- Google фактически обеспечивает запись на боковой панели для нашей железнодорожной станции. Идеальный.
- Яндекс хорошо показывает правильное местоположение в первых двух результатах, но не определяет местоположение напрямую.
- Bing тоже работает относительно хорошо, но также не называет название станции.
- TinEye дает нулевые результаты. Справедливости ради, это ожидаемо, так как картинка уникальна.
 Идеальный.
Идеальный.Фрагмент некоторых форумов Flair
- Google Отвели. Результаты представляют собой все монохромные изображения случайных тем.
- яндекс делает так же плохо но хоть держит темы к кнопкам.
- Bing тоже не работает, мы получаем случайные метки и кнопки.
- TinEye спешит на помощь! Мы получаем несколько результатов, которые указывают на правильный источник.
Резюме
Как указано в полезной таблице выше, у каждой поисковой системы есть сильные и слабые стороны. Также помните, что ни одна из этих поисковых систем не индексирует глубоко Instagram, Twitter, Facebook и другие социальные сети, поэтому таким образом вы не получите сверхспособности OSINT. При проведении расследования важно использовать все эти поисковые системы, поскольку в противном случае вы, скорее всего, упустите корреляцию. Кроме того, я использовал Hunchly, чтобы отслеживать обратный поиск изображений во время работы над этим сообщением в блоге, и настоятельно рекомендую попробовать его, если вы проводите расследования, связанные с прыжками по всему Интернету.
Итак, давайте послушаем несколько предложений для следующего раунда сообщений в блоге! Оставьте комментарий ниже или свяжитесь с нами в Twitter (@qrbounty и @dreadphones) со своими идеями. Я пропустил отличную поисковую систему? Дай мне знать!
Отклоненные заголовки для этого сообщения в блоге
- «Четыре алгоритма поиска изображений входят в [‘ДВЕРЬ’, ‘ПИВО’, ‘ТАБУРЕТ’]»
- Буквально все сделали это фото, уже убрали свой мобильный телефон и наслаждаемся поездкой
- Туда и обратно
- Перевернуть и перевернуть
- Прекратите использовать один и тот же аватар для всех ваших учетных записей хакерского форума
- 4 лучших сайта для реверсирования изображений, которые вам нужны в жизни ПРЯМО СЕЙЧАС
- Как удалить все сообщения блога в блоге вашей компании
- Как восстановить все сообщения блога в блоге вашей компании
- Почему мне вообще дали доступ к блогу
Права на изображения принадлежат их правообладателям. Центральный железнодорожный вокзал Милана. Фотография предоставлена одним из членов нашей команды
Центральный железнодорожный вокзал Милана. Фотография предоставлена одним из членов нашей команды
Яндекс Публикует ЯЛМ 100Б. Это крупнейшая нейронная сеть, похожая на GPT, с открытым исходным кодом | Михаил Хрущев | Яндекс
В последние годы крупномасштабные языковые модели на основе трансформеров стали вершиной нейронных сетей, используемых в задачах НЛП. С каждым месяцем они растут в масштабе и сложности, но для обучения таких моделей нужны миллионы долларов, лучшие специалисты и годы разработки. Вот почему только крупные ИТ-компании имеют доступ к этой ультрасовременной технологии. Однако исследователям и разработчикам во всем мире нужен доступ к этим решениям. Без новых исследований их рост может замедлиться. Единственный способ избежать этого — поделиться передовым опытом с сообществом разработчиков.
Мы уже больше года используем языковые модели семейства YaLM в голосовом помощнике Алиса и Поиске Яндекса. Сегодня мы сделали нашу самую большую модель YaLM, которая использует 100 миллиардов параметров, доступной бесплатно. Нам потребовалось 65 дней, чтобы обучить модель на пуле из 800 видеокарт A100 и 1,7 ТБ онлайн-текстов, книг и множества других источников. Мы опубликовали нашу модель и полезные материалы на GitHub под лицензией Apache 2.0, которая разрешает как исследовательское, так и коммерческое использование. В настоящее время это крупнейшая в мире нейронная сеть, подобная GPT, бесплатно доступная для английского языка.
Нам потребовалось 65 дней, чтобы обучить модель на пуле из 800 видеокарт A100 и 1,7 ТБ онлайн-текстов, книг и множества других источников. Мы опубликовали нашу модель и полезные материалы на GitHub под лицензией Apache 2.0, которая разрешает как исследовательское, так и коммерческое использование. В настоящее время это крупнейшая в мире нейронная сеть, подобная GPT, бесплатно доступная для английского языка.
В этой статье мы поделимся не только моделью, но и нашим опытом ее обучения. Вы можете подумать, что с суперкомпьютером обучение крупномасштабных моделей — это проще простого. К сожалению, это не так. Здесь мы расскажем вам, как нам удалось обучить такую огромную языковую модель и как мы вдвое сократили время обучения без ущерба для стабильности. Многие вещи, описанные ниже, можно применять и для обучения небольших моделей.
В контексте крупномасштабных нейронных сетей 10-процентное увеличение скорости обучения может сэкономить вам неделю работы в кластере с высокой ценностью. Здесь мы расскажем вам, как увеличить скорость тренировки более чем в два раза.
Здесь мы расскажем вам, как увеличить скорость тренировки более чем в два раза.
Итерации обучения обычно состоят из следующих шагов:
- Подготовка пакета
- Запуск прямого распространения: расчет функций активации и потерь
- Запуск обратного распространения: расчет градиентов
- Запуск этапа шага для обновления весов модели
Давайте посмотрим, как можно ускорить эти этапы.
Поиск узких мест
Чтобы увидеть, как используется время обучения, следует использовать профилировщик. В PyTorch этим занимается модуль torch.autograd.profiler (см. статью). Вот пример трассировки, которую мы получили от профилировщика:
Этот след был создан небольшой 12-слойной нейронной сетью. Вы можете увидеть этапы вперед вверху и этапы назад внизу. Что не так с этим следом? Одна операция занимает слишком много времени, около 50% всего времени обучения. Оказалось, что мы забыли изменить размер встраивания токена при копировании обучающей конфигурации для нашей большой модели.
Это привело к чрезмерному умножению матриц в конце сети. Уменьшив размер встраивания, мы значительно ускорили процесс обучения.Профилировщик также помог нам найти более серьезные проблемы, поэтому мы рекомендуем использовать его часто.
Использовать быстрые типы данных
Первое, что влияет на скорость обучения и вывода, — это тип данных, используемый для хранения модели и выполнения вычислений. Мы используем четыре типа данных:
- Формат одинарной точности, fp32: обычный формат с плавающей запятой. Это очень точно, но занимает четыре байта, замедляя вычисления. Это тип вашей модели PyTorch по умолчанию.
- Формат половинной точности, fp16: 16-битный тип данных, который намного быстрее, чем fp32, и потребляет вдвое меньше памяти.
- bfloat16, еще один 16-битный тип: по сравнению с fp16 он предоставляет на 3 бита меньше для мантиссы и на 3 бита больше для экспоненты. В результате формат может принимать более широкие диапазоны значений, но страдает от потери точности в числовых операциях.
- Формат TensorFloat, tf32: 19-битный тип данных, который объединяет экспоненту из bf16 и мантиссу из fp16. Он потребляет те же четыре байта, что и fp32, но намного быстрее.
На видеокартах A100 и новее 16-битные типы в 5 раз быстрее, чем fp32, и в 2,5 раза быстрее, чем tf32. Если вы используете карту A100, то вместо fp32 всегда используется tf32, если вы явно не укажете иное.
В старых видеокартах bf16 и tf32 не поддерживаются, а fp16 всего в два раза быстрее, чем fp32. Несмотря на это, это все еще огромный выигрыш в производительности. Всегда имеет смысл выполнять вычисления в формате половинной точности или в формате bf16, хотя у этого подхода есть свои недостатки. Мы обсудим это позже.
Ускорение операций на графическом процессоре
В этой статье дается хорошее объяснение операций на графическом процессоре и способов их ускорения. Здесь мы процитируем пару основных идей оттуда.
Использовать GPU полностью
Для начала разберемся, как выглядит расчет одного CUDA-ядра на GPU.
Аналогия с фабрикой из этой статьи помогает проиллюстрировать это:У вашего графического процессора есть склад (память) и фабрика (вычисления). При выполнении ядра вычисление запрашивает соответствующие данные из памяти, вычисляет результат и записывает его обратно в память.
Что произойдет, если ваш завод работает на половину своей мощности?
Как и на заводе по производству кирпича и минометов, половина ресурсов графического процессора простаивает. Как исправить это во время тренировки? Самый простой способ — увеличить размер пакета до .
Для небольших моделей увеличение размера партии в N раз может принести многократное увеличение скорости обучения, хотя сама итерация замедлится. Для крупномасштабных моделей с миллиардами параметров также можно получить небольшой выигрыш от увеличения размера пакета.
Уменьшить взаимодействие с памятью
Вторая идея из статьи заключается в следующем. Предположим, у нас есть три ядра, которые обрабатывают одни и те же данные в конвейере:
В этом случае время используется не только для вычислений, но и для доступа к памяти: эти операции имеют свою цену.
Чтобы уменьшить количество этих операций, вы можете сплавить свои ядра:Как? Есть несколько способов:
1. Использовать torch.jit.script. Используя этот простой атрибут, вы можете скомпилировать код функции в одно ядро. В приведенном ниже коде мы объединили три операции: добавление тензора, удаление и добавление другого тензора.
Этот подход дал нам увеличение скорости обучения на 5%.
2. Вы можете написать свои собственные ядра CUDA. Таким образом, вы можете не только объединить свои операции, но и оптимизировать использование памяти и избежать ненужных операций. Однако написание этого кода требует очень специфических знаний, а разработка ядра может оказаться слишком дорогой.
3. Либо можно использовать готовые ядра CUDA. Давайте быстро взглянем на ядра в библиотеках Megatron-LM и DeepSpeed (мы их часто используем):
- Внимание softmax с треугольной маской обеспечивает ускорение на 20–100%. Прирост скорости также особенно высок в небольших сетях, когда вы используете fp32 в своих вычислениях.
- Внимание softmax с произвольной маской обеспечивает ускорение до 90%.
- Fused LayerNorm — это объединенная версия LayerNorm в fp32. Мы его не использовали, но он тоже должен дать выигрыш в скорости.
- Трансформаторы DeepSpeed представляют собой трансформатор с полностью плавкими предохранителями. Он обеспечивает ускорение, но его крайне сложно масштабировать и поддерживать, поэтому мы его не используем.
Используя разные виды сплавленных ядер, мы ускорили процесс обучения более чем в 1,5 раза.
Dropouts
Если у вас много данных и нет переобучения при dropout == 0, отключите dropouts! Это увеличило скорость наших вычислений на 15%.
Случай с несколькими графическими процессорами
Что изменится, если вы запустите несколько графических процессоров? Теперь наш процесс выглядит следующим образом:
- Подготовьте пакет
- Вперед
- Назад
- all_reduce градиенты: усредните градиенты на ваших видеокартах, чтобы объединить их ресурсы
- Шаг: Обновите веса модели
Усреднение всех градиентов требует времени.
Каждый графический процессор должен отправлять и получать как минимум столько градиентов, сколько у вас есть параметров в вашей сети. Давайте посмотрим, как мы можем значительно ускорить эту и ступенчатую стадию.Связь
Как работает оптимальная связь? Используемая нами библиотека NVIDIA NCCL вычисляет обмен данными при инициализации и позволяет графическим процессорам обмениваться данными по сети без каких-либо посредников ЦП. Это обеспечивает максимальную скорость связи. Вот статья NVIDIA об этой библиотеке.
В коде это выглядит так:
Коммуникации NCCL очень быстрые, но даже с ними скорость этапа all_reduce займет много времени. ZeRO помогает нам ускорить его еще больше.
ZeRO
ZeRO означает оптимизатор нулевой избыточности.
В левой части картинки вы видите стандартную тренировку на нескольких GPU. В стандартной схеме мы распределяем все параметры и состояния оптимизации, а также усредненные градиенты между нашими процессами.
Это стоит нам много памяти.Блок-схема высокого уровня ZeRO показана справа. Каждому процессу мы назначаем группу параметров. Для этих параметров процесс всегда сохраняет значения и состояния оптимизатора, и только этот процесс может их обновлять. Таким образом, вы можете сэкономить огромные объемы памяти, которые теперь могут быть выделены для больших пакетов. Однако это добавляет новый этап: all_gather weights. Нам нужно собрать все параметры сети в каждом процессе, чтобы запустить прямой и обратный этапы. Теперь сложность операций после расчета градиентов будет следующей:
- градиенты all_reduce: O(N), где N — количество параметров.
- шаг: O(N/P), где P — количество процессов. Это уже приличный разгон.
- параметры all_gather: O(N).
Как видите, мы ускорили один этап, но за счет добавления новых, тяжелых операций. Так как же нам их ускорить? Просто: запускайте их асинхронно!
Соберите свои слои асинхронно один за другим во время предварительной стадии:
- Собираем первый слой для всех процессов.
- Собирая второй слой, мы запускаем предварительную стадию для первого слоя.
- Собирая третий слой, мы запускаем передний этап для второго слоя.
И так далее, пока не закончим все этапы вперед. Вы можете ускорить обратную стадию почти таким же образом.
Это увеличило скорость наших моделей на 80%! Даже на небольших моделях (100M на 16 GPU) мы увидели ускорение на 40–50%. Для этого подхода требуется довольно быстрая сеть, но если она у вас есть, вы можете значительно ускорить обучение на нескольких GPU.
Результат
Мы применили четыре подхода к нашему тренировочному процессу:
- Мы объединили часть наших операций: +5% скорости
- Мы использовали ядро внимания softmax с треугольной маской: +20–80%
- Мы отключено отсев: +15%
- Мы применили ZeroRO: +80%
Неплохо. Давайте двигаться дальше.
Долгая итерация — не единственное препятствие для обучения действительно большой модели.
Может показаться, что если у вас достаточно вычислительной мощности, вы можете просто начать обучение модели, отправиться в отпуск на два месяца, а по возвращении вас будет ждать уже готовая модель. Однако модели такого масштаба достаточно хрупкие и склонны к расхождению. Что такое дивергенция и как ее контролировать?Что такое дивергенция?
Допустим, вы запустили тренировку, посмотрели на графики и увидели, что убыток уменьшается. Первый день, второй день, третий день, все еще уменьшается. Затем, утром четвертого дня, вы смотрите на график потерь, и он выглядит так:
Сейчас потери выше, чем через несколько часов после начала тренировки. Более того, модель буквально забыла все, что знала. Это непоправимо: дни тренировок насмарку.
Что случилось?
Первые наблюдения
Мы заметили три вещи:
1. Оптимизатор LAMB гораздо менее склонен к расхождениям, чем Адам.
2. Снижая скорость обучения, мы можем решить проблему расхождения.
Но не все так просто:- Чтобы правильно подобрать параметр lr, нужно многократно перезапускать процесс обучения.
- Уменьшение lr часто замедляет обучение: например, здесь двукратное уменьшение lr привело к замедлению на 30%:
3. fp16 более подвержен проблемам расхождения, чем fp32. В основном это было связано с переполнением значений fp16 в наших функциях активации и градиентах. Максимальное абсолютное значение fp16 равно 65535. Переполнение привело к NaN в значениях функции потерь.
Термометры
Одной из вещей, которые мы долгое время использовали для продолжения обучения, были термометры. Измерялись максимумы и минимумы функций активации в различных сегментах сети, а также глобальная норма градиентов. Вот пример значений термометра для дивергентной тренировки:
Видно, что начиная примерно с 14 000 итераций, максимумы матмуля во внимании стали резко расти. Этот рост является причиной дивергенции. Если вы откатите обучение до 13 000 итераций и пропустите ошибочные пакеты, вызвавшие расхождение, или уменьшите скорость обучения, вы можете значительно снизить вероятность повторного расхождения.
У этого подхода есть два недостатка:
- Он не устраняет 100% расхождения.
- Вы тратите драгоценное время на откат обучения. Это конечно лучше, чем совсем отказаться от дивергентной тренировки, но все же.
Позже мы ввели некоторые приемы, которые уменьшили вероятность расхождения до такой степени, что позволили нам обучить множество моделей разных размеров, включая 100B.
Стабилизации. BFloat 16
BFloat 16 не переполняется даже при больших значениях градиентов и активаций. Вот почему этот формат является проверенным вариантом для хранения весов и выполнения вычислений. К сожалению, он недостаточно точен, поэтому произвольные арифметические операции могут накапливать ошибки, приводящие к замедлению обучения или другому виду расхождений.
Чтобы компенсировать расхождение, мы начали просчитывать следующие слои и операции в tf32 (или fp32 на старых видеокартах):
- Softmax во внимание (вот где наши ядра пригодились), softmax на токенах до функции потери .
- Все функции LayerNorm.
- Все операции с Residual: так мы избежали накопления ошибок и перемещения градиентов вглубь сети.
- all_reduce градиентов, о которых мы упоминали ранее.
Все эти стабилизации замедлили обучение всего на 2%.
Стабилизации. LayerNorm
В статьях о BERT и GPT использовался подход, известный сейчас как post-layernorm (слева на картинке). Однако с точки зрения стабильности и скорости сходимости на больших моделях pre-LayerNorm показал себя превосходно (справа на картинке). Итак, для наших моделей мы используем pre-LayerNorm.
BigScience просветила нас о неожиданном варианте стабилизации: вводя layernorm в самом начале сети, после встраивания, можно также существенно снизить вероятность коллапса.
Стабилизация. Curriculum Learning
Мы также использовали подход из статьи Curriculum Learning. Мы хотим обучить нашу нейронную сеть на большой партии и большой длине строки, но мы начинаем с обучения на маленькой партии и небольшой длине строки, а затем постепенно увеличиваем их по мере обучения.
Этот подход имеет два преимущества:
- Функция потерь довольно быстро падает в самом начале, независимо от количества токенов, видимых модели на каждой итерации. Поскольку мы уменьшаем количество вычислений в начале обучения, мы намного быстрее проходим этот этап плато потерь.
- Авторы статьи утверждают, что такой подход приводит к стабилизированному обучению.
Стабилизации. Резюме
Мы реализовали следующие подходы:
- Мы приняли bf16 в качестве основного типа для весов
- Мы провели вычисления, критичные к точности, в tf32
- Мы ввели pre-LayerNorm
- Мы поставили LayerNorm сразу после встраивания
- Мы
б/у Curriculum learning
 Это привело к чрезмерному умножению матриц в конце сети. Уменьшив размер встраивания, мы значительно ускорили процесс обучения.
Это привело к чрезмерному умножению матриц в конце сети. Уменьшив размер встраивания, мы значительно ускорили процесс обучения.
 Аналогия с фабрикой из этой статьи помогает проиллюстрировать это:
Аналогия с фабрикой из этой статьи помогает проиллюстрировать это: Чтобы уменьшить количество этих операций, вы можете сплавить свои ядра:
Чтобы уменьшить количество этих операций, вы можете сплавить свои ядра: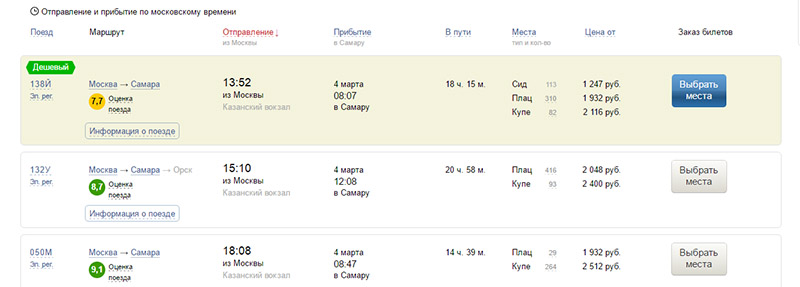
 Каждый графический процессор должен отправлять и получать как минимум столько градиентов, сколько у вас есть параметров в вашей сети. Давайте посмотрим, как мы можем значительно ускорить эту и ступенчатую стадию.
Каждый графический процессор должен отправлять и получать как минимум столько градиентов, сколько у вас есть параметров в вашей сети. Давайте посмотрим, как мы можем значительно ускорить эту и ступенчатую стадию. Это стоит нам много памяти.
Это стоит нам много памяти.
 Может показаться, что если у вас достаточно вычислительной мощности, вы можете просто начать обучение модели, отправиться в отпуск на два месяца, а по возвращении вас будет ждать уже готовая модель. Однако модели такого масштаба достаточно хрупкие и склонны к расхождению. Что такое дивергенция и как ее контролировать?
Может показаться, что если у вас достаточно вычислительной мощности, вы можете просто начать обучение модели, отправиться в отпуск на два месяца, а по возвращении вас будет ждать уже готовая модель. Однако модели такого масштаба достаточно хрупкие и склонны к расхождению. Что такое дивергенция и как ее контролировать?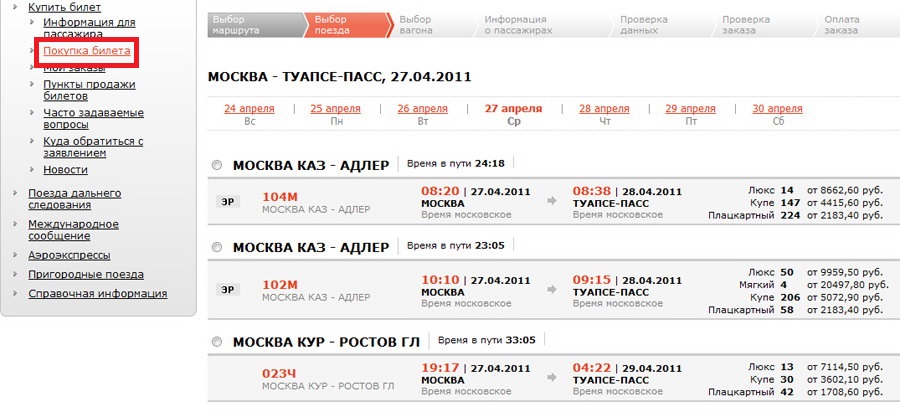 Но не все так просто:
Но не все так просто:


В результате мы обучаем наши модели без расхождений уже более 6 месяцев. Модели бывают разных размеров. Эти стабилизации помогли нам обучить модель со 100 миллиардами параметров, которыми мы теперь рады поделиться с разработчиками и исследовательским сообществом.